
Whishper is an awsome project built on top of LibreTranslate, that we can SelfHost to make local audio transcription.
The Whishper Project
Whishper - Open-source, local-first audio transcription and subtitling with UI
SelfHosting Whishper
🚀 Self-Hosting Whisper Project with Docker: Step-by-Step Guide
-
CPU: Surprise! No GPU is required for this setup. You don’t need an expensive GPU to dive into AI projects!
-
Docker Installation: Make sure Docker is installed on your machine. Docker simplifies the deployment of complex AI projects and provides a consistent environment across different platforms.
Really, Just Get Docker 🐋👇
You can install Docker for any PC, Mac, or Linux at home or in any cloud provider that you wish. It will just take a few moments. If you are on Linux, just:
apt-get update && sudo apt-get upgrade && curl -fsSL https://get.docker.com -o get-docker.sh
sh get-docker.sh
#sudo apt install docker-compose -yAnd install also Docker-compose with:
apt install docker-compose -yWhen the process finishes, you can use it to self-host other services as well. You should see the versions with:
docker --version
docker-compose --version
#sudo systemctl status docker #and the status-
Portainer Guide (Optional): If you’re not comfortable with Docker CLI commands, consider using Portainer, a web-based management interface for Docker. Follow the guide to set up Portainer and manage Docker containers with ease.
- Install Portainer on your system by following these simple steps
-
Whisper Docker Configuration File: This file contains the settings and parameters required to run the Whisper project in a Docker container.
Whishper with Docker
You will need the docker-compose configuration and the .env to specify your variables
You can always have a look at Whishper Official Docs
Whishper Docker-Compose
This configuration file for Whisper is kind of long, but dont worry, you can just copy paste it:
#version: "3.9"
services:
mongo:
image: mongo
env_file:
- .env
restart: unless-stopped
volumes:
- ./whishper_data/db_data:/data/db
- ./whishper_data/db_data/logs/:/var/log/mongodb/
environment:
MONGO_INITDB_ROOT_USERNAME: ${DB_USER:-whishper}
MONGO_INITDB_ROOT_PASSWORD: ${DB_PASS:-whishper}
expose:
- 27017
command: ['--logpath', '/var/log/mongodb/mongod.log']
translate:
container_name: whisper-libretranslate
image: libretranslate/libretranslate:latest
restart: unless-stopped
volumes:
- ./whishper_data/libretranslate/data:/home/libretranslate/.local/share
- ./whishper_data/libretranslate/cache:/home/libretranslate/.local/cache
env_file:
- .env
tty: true
environment:
LT_DISABLE_WEB_UI: True
LT_UPDATE_MODELS: True
expose:
- 5000
networks:
default:
aliases:
- translate
healthcheck:
test: ['CMD-SHELL', './venv/bin/python scripts/healthcheck.py']
interval: 2s
timeout: 3s
retries: 5
whishper:
pull_policy: always
image: pluja/whishper:${WHISHPER_VERSION:-latest}
env_file:
- .env
volumes:
- ./whishper_data/uploads:/app/uploads
- ./whishper_data/logs:/var/log/whishper
container_name: whishper
restart: unless-stopped
networks:
default:
aliases:
- whishper
ports:
- 8082:80
depends_on:
- mongo
- translate
environment:
PUBLIC_INTERNAL_API_HOST: "http://127.0.0.1:80"
PUBLIC_TRANSLATION_API_HOST: ""
PUBLIC_API_HOST: ${WHISHPER_HOST:-}
PUBLIC_WHISHPER_PROFILE: cpu
WHISPER_MODELS_DIR: /app/models
UPLOAD_DIR: /app/uploads
CPU_THREADS: 4
Whishper .env
# Libretranslate Configuration
## Check out https://github.com/LibreTranslate/LibreTranslate#configuration-parameters for more libretranslate configuration options
LT_LOAD_ONLY=es,en,fr
# Whisper Configuration
WHISPER_MODELS=tiny,small
WHISHPER_HOST=http://127.0.0.1:8082
# Database Configuration
DB_USER=whishper
DB_PASS=whishper
💻 Easy Deployment with Docker: Terminal or UI? You Decide!
Deployment:
-
Using Docker CLI:
- Open a terminal or command prompt.
- Navigate to the directory containing the Whisper configuration file.
- Run the Docker command to deploy Whisper using the provided configuration file.
- Monitor the deployment process for any errors or warnings.
-
Using Portainer (Optional):
- Not comfortable with the terminal? Remember, there’s an alternative!
- Access the Portainer web interface in your browser.
- Navigate to the “Containers” section and click on “Add Container.”
- Provide the necessary details, including the name of the container, the image (Whisper), and any additional configuration settings.
- Upload the Whisper configuration file if required.
- Click on “Deploy Container” to start the deployment process.
Just configure your desired variables and deploy whishper with:
docker-compose up -d
Your Whishper instance is ready will be waiting for you at http://localhost:8082
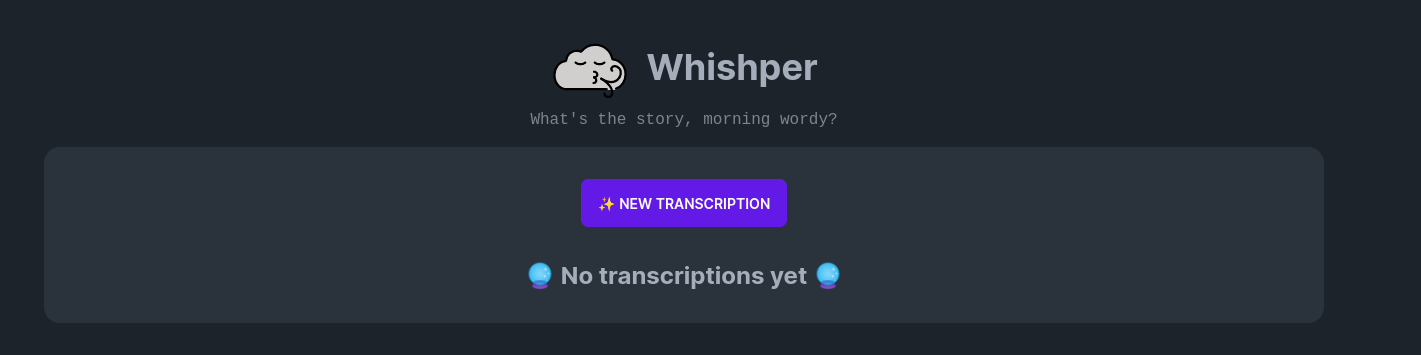
This is how the Whishper interface looks like:
FAQ
Other F/OSS Audio Transcription Tools
- Bark
- Audiocraft
- LibreTranslate Source Code
How to Install AudioCraft?
- Get Python installed
- Get Familiar with Virtual Environments
Installing AudioCraft with Python Step by Step 👇
python3 -m venv audiocraft source audiocraft/bin/activate apt install ffmpeg git clone https://github.com/facebookresearch/audiocraft.git ./audio cd audio python -m pip install -r requirements.txt pip install rich python -m demos.musicgen_app --share #deactivate
And the Gradio UI will be available at http://localhost:7860
How to install Bark?
Testing Bark with Python Step by Step 👇
#pip install --upgrade setuptools wheel
pip install git+https://github.com/suno-ai/bark.git
pip install git+https://github.com/huggingface/transformers.git
#pip install IPython
Try Bark Audio Generation with:
python -m bark --text "Hello, my name is Suno." --output_filename "example.wav"
or directly in Python:
from transformers import AutoProcessor, BarkModel
processor = AutoProcessor.from_pretrained("suno/bark")
model = BarkModel.from_pretrained("suno/bark")
voice_preset = "v2/en_speaker_6"
inputs = processor("Hello, my dog is cute", voice_preset=voice_preset)
audio_array = model.generate(**inputs)
audio_array = audio_array.cpu().numpy().squeeze()
import scipy
sample_rate = model.generation_config.sample_rate
scipy.io.wavfile.write("bark_out.wav", rate=sample_rate, data=audio_array)